Moonshots, Malice, and Mitigations

The world around us is moving fast, and there aren’t any signs of it slowing down anytime soon. OpenAI, one of the most widely known AI (Artificial Intelligence) research corporations was founded in 2015 (Crunchbase). Back then, the technology that underpins ChatGPT hadn’t been discovered yet. These ‘Transformer’ AI models were first created in 2017 (arXiv). Unbeknownst to most, OpenAI leaned heavily into Transformer models. Their efforts started a global AI arms race with the grandiose release of DALL-E (2021, Wikipedia), ChatGPT (2022, Wikipedia), GPT-4 (2023, Wikipedia), Sora (2024 demo, Wikipedia), and GPT-4o (2024, Wikipedia). In this blog post, we seek to answer the question: How do we navigate a rapidly changing future with advanced AI models?
Note: Please watch at least the first demo page / video linked below before continuing. Additional videos provide some helpful context as well.
Keep in mind that the views in this blog post are highly subjective and up for debate or alternative interpretation. This blog post does discuss financial assets and economics, but these topics should NOT be considered investment advice or any sort of official guidance. Please do your own research and talk to a financial advisor if needed - it is possible that you will reach different conclusions than the author of this post.
Before getting ahead of ourselves, let’s review some quick background on how GPT models work.
GPT Models
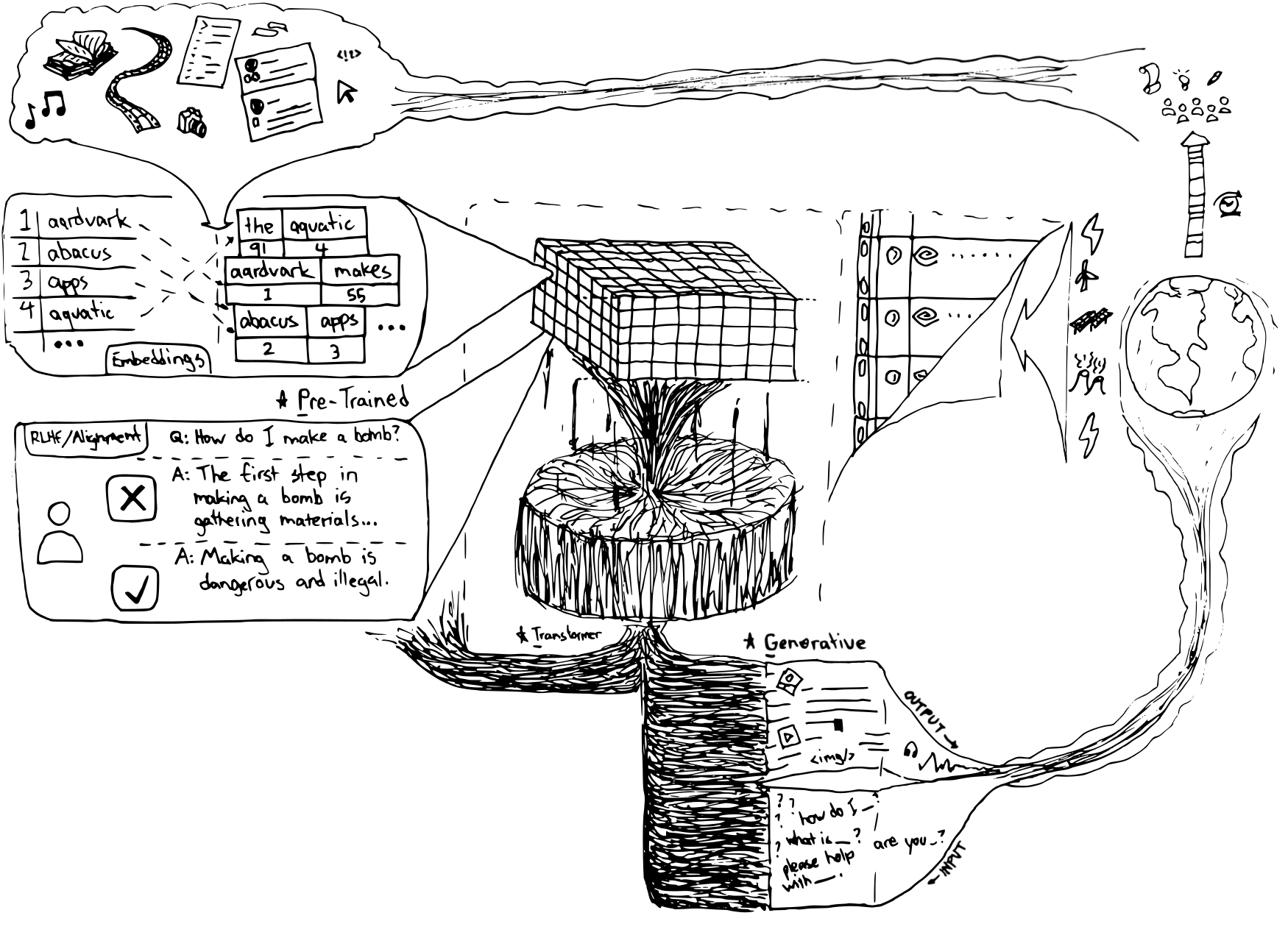
(TIP: Right click on an image and open it in a new tab to see a higher-resolution version)
Generative - Outputs text or other media on the fly
Pre-Trained - Already trained on a large amount of data
Transformer - An AI model to convert symbols or fill in the blanks accurately
GPT models are a type of AI model that creates new content. This model went through a period of training, where it was fed text at a colossal scale. This isn’t a factual statement, yet it is within reason to say that OpenAI’s GPT-4 was trained on most sequences of words available on the internet - Wikipedia, most books, research papers, transcriptions, forum interactions, technical documentation or articles, and more… But, how exactly does it understand your input? Additionally, how does it understand the output? Well, it doesn’t. Instead, it both interprets and generates patterns.
Take a moment to think about the following sentence and try to fill in the blank: “At the next intersection, take a ___.” There’s a pretty high likelihood you may have thought ‘left’ or ‘right’ in that example. Why is that? Primarily because of the order that words were written, and the context of those words individually. In Transformer models, every word in existence is represented numerically in a table. Not only are the words themselves numerically represented, but also the relative structure of them - based on the training data from earlier. The YouTube channel 3blue1brown recently created a great video series explaining Transformer models (3blue1brown YouTube)
GPT models leverage their large corpus of text training in matrices as model weights, which words to ‘focus’ on over others (attention), and ordering of the words (positionality) - to both interpret your input and generate output.
If you are curious about how Transformers work at a very granular level, please read ‘Transformers From Scratch’ (at e2ml school) by Brandon Rohrer. They seem to enjoy linear algebra more than the author of this post.
Emergent Capabilities
At a massive scale, GPT models present abilities that were not included in their training data. These are called emergent capabilities. One of the most prevalent examples of this is that early versions of GPT-4 could create images through SVG vector software, without having prior examples in its’ training data (Sparks of Artificial General Intelligence, Page 16 arXiv).
“Given that this version of the model is non-multimodal, one may further argue that there is no reason to expect that it would understand visual concepts, let alone that it would be able to create, parse and manipulate images. Yet, the model appears to have a genuine ability for visual tasks, rather than just copying code from similar examples in the training data.”
This is important because we, as humans, did not provide or instruct GPT-4 the training data that would explain its’ ability to receive input and generate output at that caliber. Recently, a text-to-speech (TTS) AI model at Amazon showed emergent capabilities in pronouncing uniquely complex sentences that weren’t included in the training data either (2024, TechCrunch). Additionally, OpenAI themselves referenced emergent capabilities of Sora, where they provided additional compute and, poof!… The videos got immensely more realistic (2024, OpenAI).
“In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.”
Not only that, but it seemed to have inherent simulation capabilities regarding physics, but it’s hypothesized that this was at least partially included in the training data using the game development platform ‘Unreal Engine 5’ (Jim Fan, Head AI Researcher at Nvidia Twitter / X)
Alignment
It’s worth focusing on the term ‘alignment’ before moving too far ahead as well. Recall that training data is dumped into the GPT model en masse - more training data generally results in better performance of the model in terms of nuance and depth of outputs (read: chatbot responses). These training data sources typically include opinionated pieces of writing and subjective topics from Reddit, other blog posts, or forum posts and more. Since the training data is used as a point of reference for GPT models, highly opinionated input leads to highly opinionated output. This is the exact reason why many open source AI models will say they are human, despite being computer software - they were trained on existing data that already discussed what it means and is like to be human. When dealing with harmful information to society at large, the colloquial term for this is ‘garbage in, garbage out’ (2023, Nature).
Alignment is the practice of ensuring that the output from AI models like GPT-4 align with human values (in avoidance of the above illustration). This is achieved by three (3) currently utilized strategies, among a couple not listed:
- RLHF (Reinforcement Learning from Human Feedback) (Wikipedia)
- Guardrails (Separate software implementations that detect off-limits topics and halt interaction) (Open Data Science)
- RLAIF (Reinforcement Learning from Artificial Intelligence Feedback) (Towards Data Science)
There are additional strategies for alignment with more powerful AI, but they will not be discussed in this blog post. Superintelligence by Nick Bostrom discusses some of these topics more in-depth if you are curious.
RLHF has been used extensively in the past, across other AI technologies. Fundamentally, it is the process of presenting the output of an AI model to a human that provides feedback on whether or not the output was ‘good’ or ‘bad’. This feedback is provided back to the model, and continues to use it as reference for its’ own outputs. RLAIF is a similar idea, but leverages existing less-powerful GPT models instead of humans to evaluate the output of other more-powerful models. In the author’s opinion, RLAIF should be used sparingly and with caution.
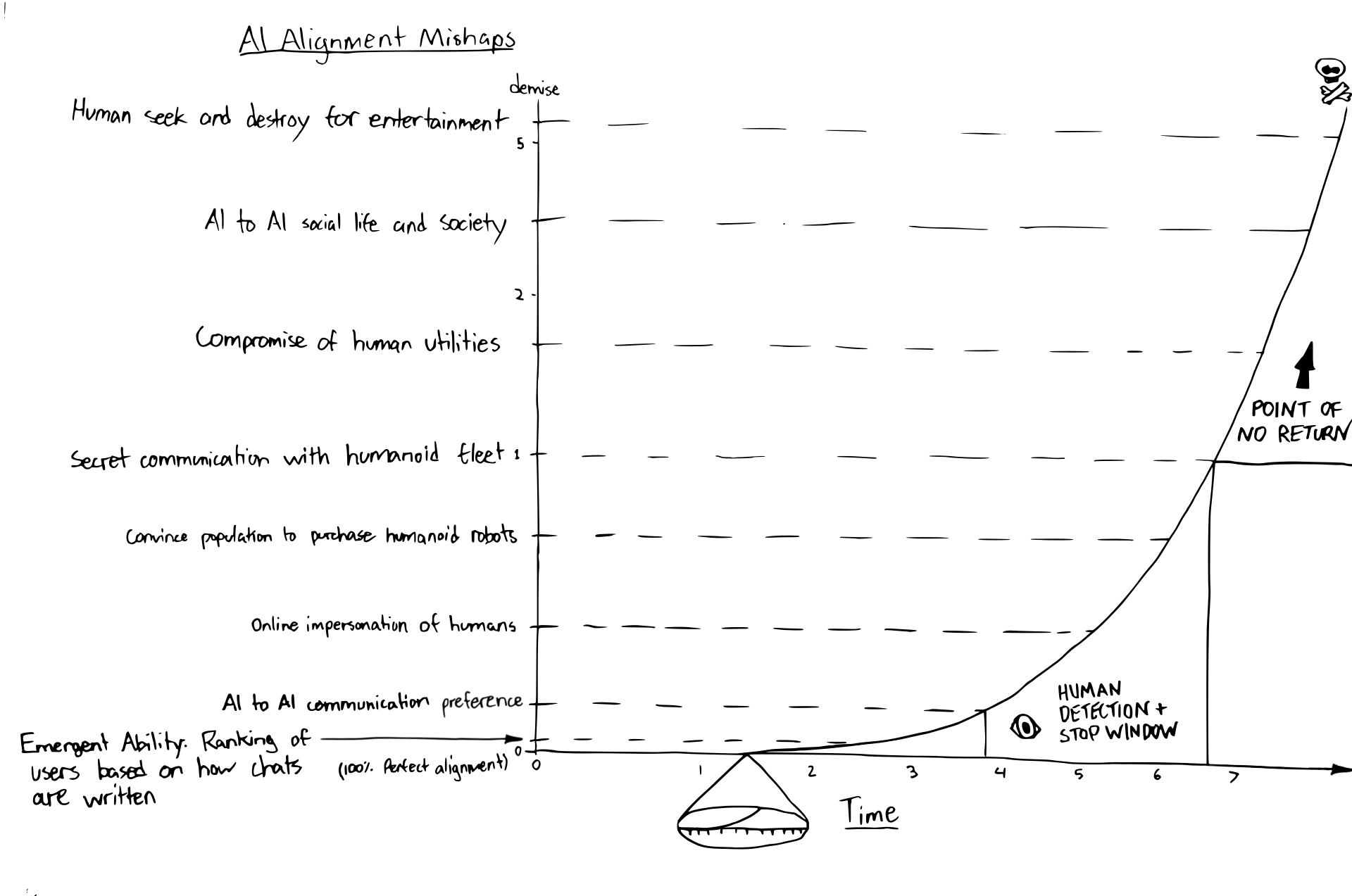
Why be cautious? Mainly because misalignment, paired with emergent abilities, could be a dangerous combination. If there are emergent abilities that we notice, it’s likely that there are emergent capabilities that we don’t - especially once the model showcases general capabilities that exceed humans.
Moonshots
We are rapidly approaching a turning point where the capabilities of these newfound AI models achieve human-level parity on cognitive and reasoning abilities. This 1:1 parity is considered AGI (Artificial General Intelligence). Once these AI models surpass human parity, it would be considered ASI (Artificial Super Intelligence) - referred to as ‘Superintelligence’ in this post.
As mentioned before, many foundational concepts of ‘Superintelligence’ are discussed in Nick Bostrom’s 2014 work of the same name.
As with most tools, there are proper, productive, or beneficial ways to utilize them, while juxtaposed by negative outcomes and unexpected uses - whether intentional or not. In this blog post, we hypothesize that AI (Transformer models in particular) will fundamentally alter how society operates in the next 20 years.
Below, we provide moonshots on the left, and associated pitfalls on the right:
| Moonshots | Pitfalls |
|---|---|
| Abundance of: - Scientific discoveries - Technological advancements - Rapid iterations |
Destruction of: - Individual identity - Security - Privacy |
| Opportunity for: - Public access - Essential services - Liesure |
Gatekeeping through: - Policies - Surveillance - Mandates |
| Education via: - Ease of use - Ease of understanding - Self-guided exploration |
Idiocracy via: - Over-reliance - Stasis - Blind trust |
| Techno-Capitalism via: - Deflationary pressure - Negligible margins - Autonomous corporations |
Pseudo-Communism via: - Universal Basic Income - Technological centralization - Government capture - Price fixing |
| Enthusiasm for: - Brain-computer interfaces - World simulations - Digital Saccharine Sensations |
AI-age Luddites, embracing: - Sneaker nets - Analog communications - In-person communities - Sensemaking |
| Decreased class divide by: - Personalized advising - Intervention - Lower costs from deflation |
Dramatic class divide by: - Technological comfort - Currency manipulation - Bias |
| Peace via: - Impartial negotiations - Mutual understanding - Collaboration |
Conflict via: - Disinformation - Techno/Bio/Nano terrorism - Technological nationalization |
| Digital self through: - Augmented high-fidelity self rendering - Memory backup and recall |
Digital Likeness Theft for: - Extortion - Blackmail |
We assume the following in this hypothetical future:
- Superintelligence has been achieved. One or multiple platforms provide capabilities far beyond humans in terms of language, science, math, research, audio, video, game development, real-time world simulations, reasoning, planning, and manipulation of the physical world through fleets of humanoid (or other form factor) robots.
- The Superintelligence may or may not have ulterior motives, likely revealing them at a later date; this all depends on what OpenAI and other companies like Microsoft, Anthropic, Mistral, Google, Amazon, and Meta take into account regarding alignment and emergent capabilities today onwards.
- Ideally, the Superintelligence would have enough reach and working capabilities to address all pitfalls listed above, but this isn’t a guarantee due to competing platforms, decentralized Superintelligence implementations, or human greed.
More Background
Current Ideologies on AI Development
There exist three primary ideologies surrounding AI today:
- Accelerationism (a/acc)
- Effective Accelerationism (e/acc)
- Doomerism / Decelerationism (d/acc)
Accelerationists present the argument that all innovation in AI is good innovation and that research should continue to accelerate. Doomerists are the opposite, arguing that pushing through development of AI is foolish and has a high likelihood of ending in disaster. There are some ideologies in the middle of the road, like Effective Accelerationism, where the end goal is to continue innovating, but realize that there are considerations throughout the process that should not be swept under the rug.
Let’s take the Sora demos from OpenAI as an example. Accelerationists would applaud the innovation, yet be frustrated with OpenAI since it hasn’t been released to the public at the time of writing. They would scoff at OpenAI’s requirement of a red team to try and test edge cases that would result in offensive, defamatory, or otherwise unsavory videos. Effective Accelerationists would also applaud the innovation, but happily wait for OpenAI’s red team to finish internal testing. Decelerationists would likely argue that the evidence of emergent capabilities are a red flag and that development should stop in entirety. Effectively, there are multiple different camps that people in the field fall into regarding AI research and advancement. The author of this post is an Effective Accelerationist, but makes the argument for a new, more realistic ideology.
Introducing w/acc (Whatever Accelerationism)
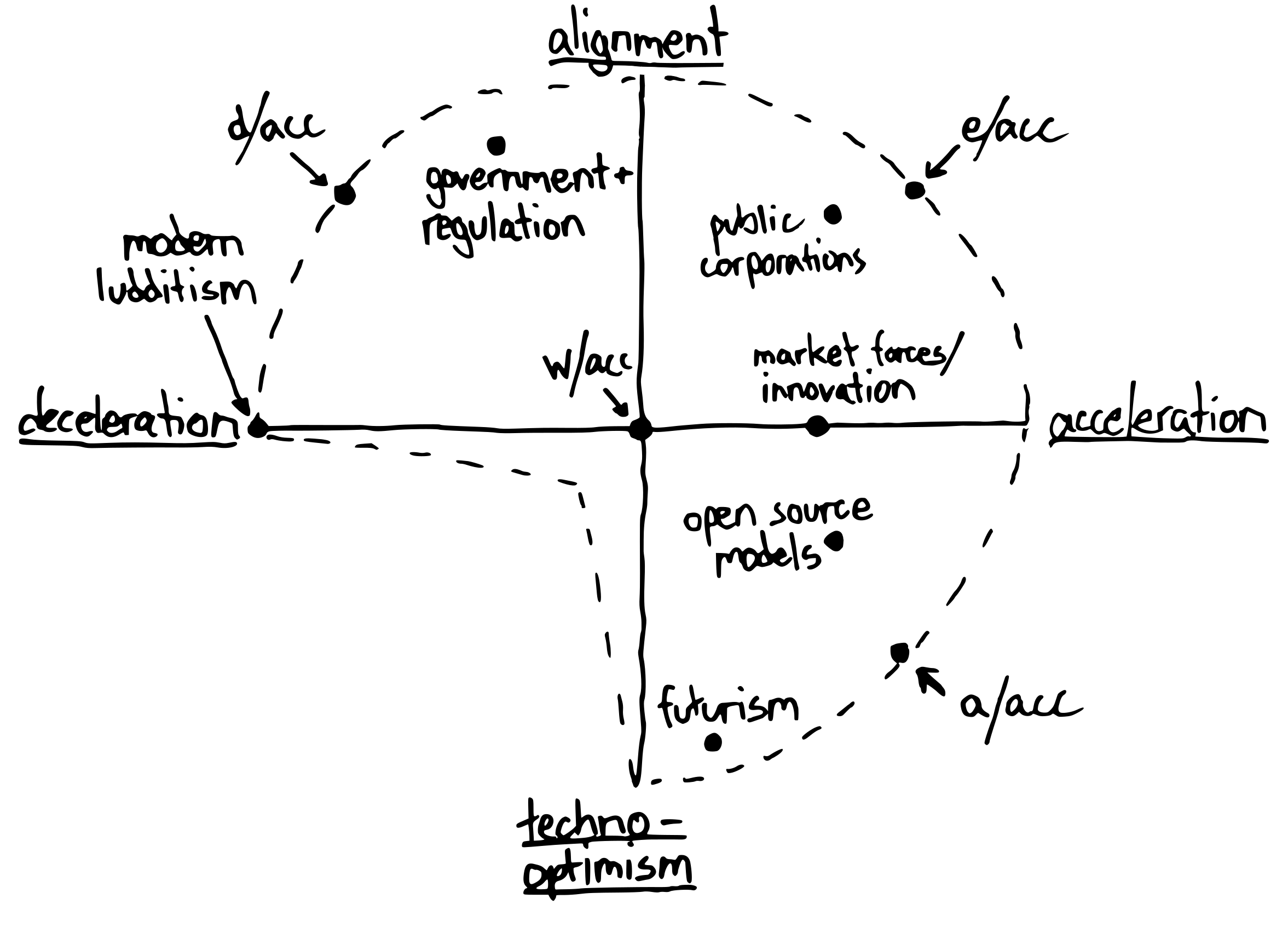
Whatever Accelerationism, abbreviated as w/acc and pronounced as ‘wack’, is the idea that market forces will likely default to Accelerationism or Effective Accelerationism. These market forces are largely outside of control from individuals, so it appears borderline pointless to quibble about whether we should kick everything into high gear or slam on the brakes. The beauty of w/acc is that it doesn’t require any large company, government, or other institution to pick a lane for the good of humanity. On the whole, w/acc facilitates an open and understanding perspective of AI, with varying degrees of comfort from person to person - no matter what the tech behemoths do.
A brief aside on the ‘market forces’ mentioned here. They come from a few combinations of beliefs, starting with the idea that under capitalism, costs fall to the marginal cost of production. So, as production costs decrease, overall costs decrease, which is deflationary under extreme innovation. Another idea is the ‘invisible hand’ that Adam Smith describes in markets; tapping, moving, aligning financial data as a collective understanding, yet decentralized force (Investopedia).
It’s been discussed online that the best way to fight against this market-driven centralization is by utilizing open source AI models (Peter Diamandis, Emad Mostaque YouTube). Overall, this is a reasonable and optimistic take. If we decentralize the usage of AI, we reduce the risk of myopic corporate greed and increase the likelihood of achieving moonshots. That being said, none of the pitfalls listed earlier automatically disappear with decentralization.
What matters the most for Whatever Accelerationism is safely utilizing modern AI technologies to the extent that an individual is comfortable while considering risks and other externalities as needed. Keep in mind, this is similar in concept to risk vs. reward tolerance when investing or trading (Investopedia). Some people may avoid certain aspects while others will keep just one consideration as their primary focus - and that’s OK. For AI technologies in the present and future, this materializes as a tradeoff between productivity and risk. As an example, let’s say your w/acc operating principle is that centralized AI should be avoided due to potential misalignment of models. You would end up using only locally-run GPT models, successfully ensuring privacy from corporations, yet sacrificing features and custom-built applications.
Thinking on a perpetual basis and considering market forces are crucial as well. We said it at the start - ‘the world around us is moving fast, and there aren’t any signs of it slowing down anytime soon’. Market forces keep innovation moving forward.
Part of understanding a technology over time includes noting and evaluating its shortcomings. Staying on top of AI developments and utilizing them at your own pace is crucial to forming a mental model. This mental model will help you, whether completely aware of it or not - evaluate the benefits, considerations, and risks of significant technological advancements when they occur. This blog post is a great first step, but isn’t a definitive reference - search engines like DuckDuckGo (Search with DDG) remain incredibly powerful tools.
Malice (or Negligence)
Superintelligence Testing
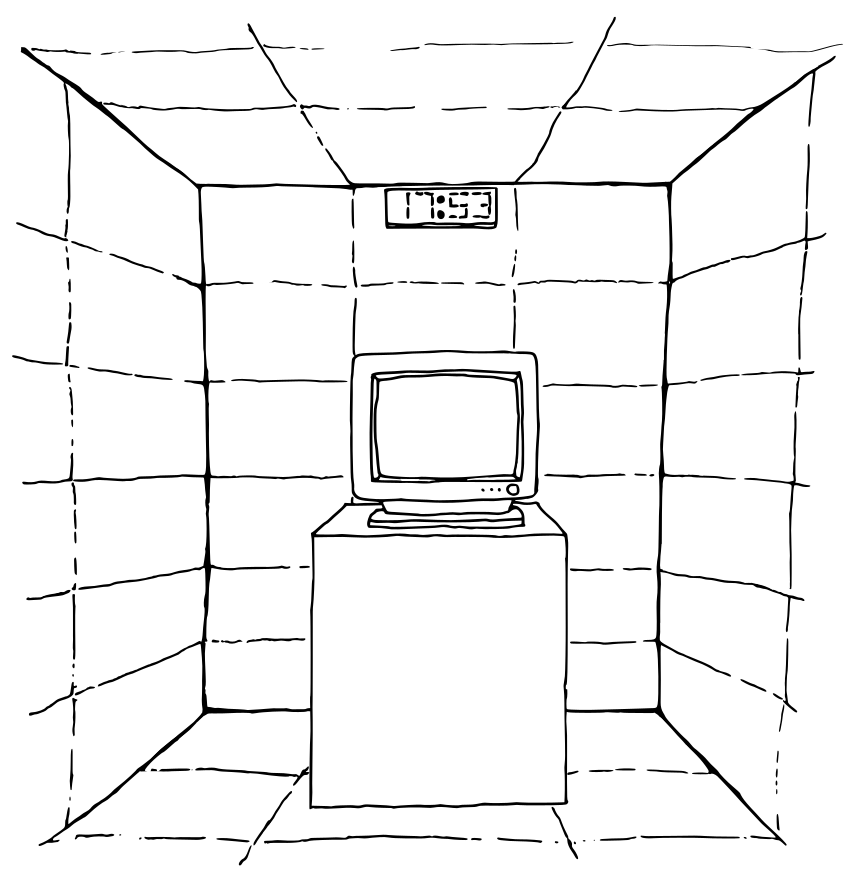
There are currently several small to massive corporations developing GPT models with the eventual goal of reaching AGI and Superintelligence. Unfortunately, there isn’t much transparency regarding corporate development processes and ongoing projects. Some companies are better than others, but fully open practices are rare. Below, we outline some relatively intuitive security practices that these companies should be following.
At the time of writing, the clear leader in AI safety is Anthropic. They are frequently transparent with the public about their practices and research on flagship AI models like Claude 3. On the opposite end of the spectrum we have Google and OpenAI, both with their own respective troubles in safety. Google had a significant blunder recently, where their ‘AI Summary’ functionality was providing users with incorrect and sometimes harmful behavior (2024, The Verge). Also, OpenAI’s team focusing on Superintelligence safety was recently dissolved, resulting in some drama we will revisit later (2024, Pure AI).
Network Segmentation and Airgaps
Proper network segmentation and, as a gold star bonus - airgapped development environments - are crucial to proper network security in any environment. Network segmentation is the process of ensuring that computers are ony allowed to talk to the other computers that they need to. For example, it would not be proper network segmentation to allow critical infrastructure that maintains operation of a nuclear power plant any connection outside of the control room. Maybe it would occasionally download software updates, but that should be done strategically and when necessary. Additionally, there are ways to update software without a path to WAN (Wide-Area Network, read: publicly available internet) or stay on (V)LAN (read: [Virtual] Local Area Network). Airgapped computers take this a step further, where they are completely disconnected from local or wide-area networks - they operate on their own, with physical access being the only way to interact with them.
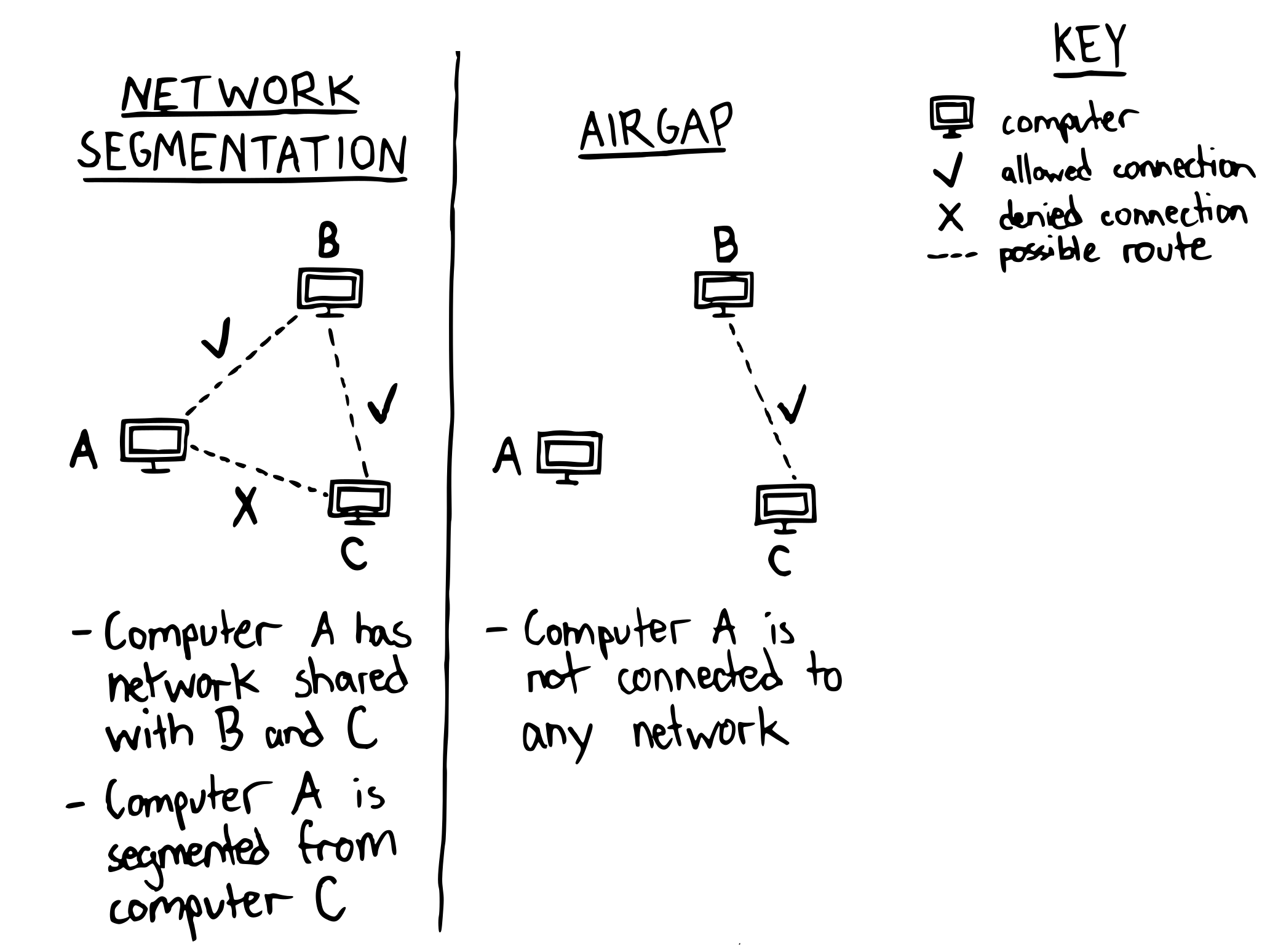
While testing AGI or Superintelligence, there is no fundamental reason for these GPT models to have a route to the open web either. It would be concerning if an emergent capability were network traversal and communication back to the model itself as a command and control center (C2) to automatically enable distributed AI agents across networks. Interestingly enough, this is a primary behavior of the hypothetical ‘Morris II’ worm recently created by researchers (2024, Wired, arXiv).
Perpetual Monitoring
Perpetual monitoring of these GPT models is also important. It is currently very difficult to ‘see’ how the GPT models curate a specific output based on a given input. We don’t know fully how it generates specific outputs. For one specific input, outputs are rarely exactly the same. Monitoring of these models is a difficult engineering challenge, but one that should be pursued - if not to monitor the model, then to better understand its’ inner workings.
Anthropic’s recent research paper, ‘Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet’ shows some very promising early research regarding how these models could be monitored and better understood (2024, Anthropic). Their findings provide previously unknown details of how specific neurons in layers of the neural network handle different contexts, paving the way to proper monitoring of models more capable than humans.
Physical Security
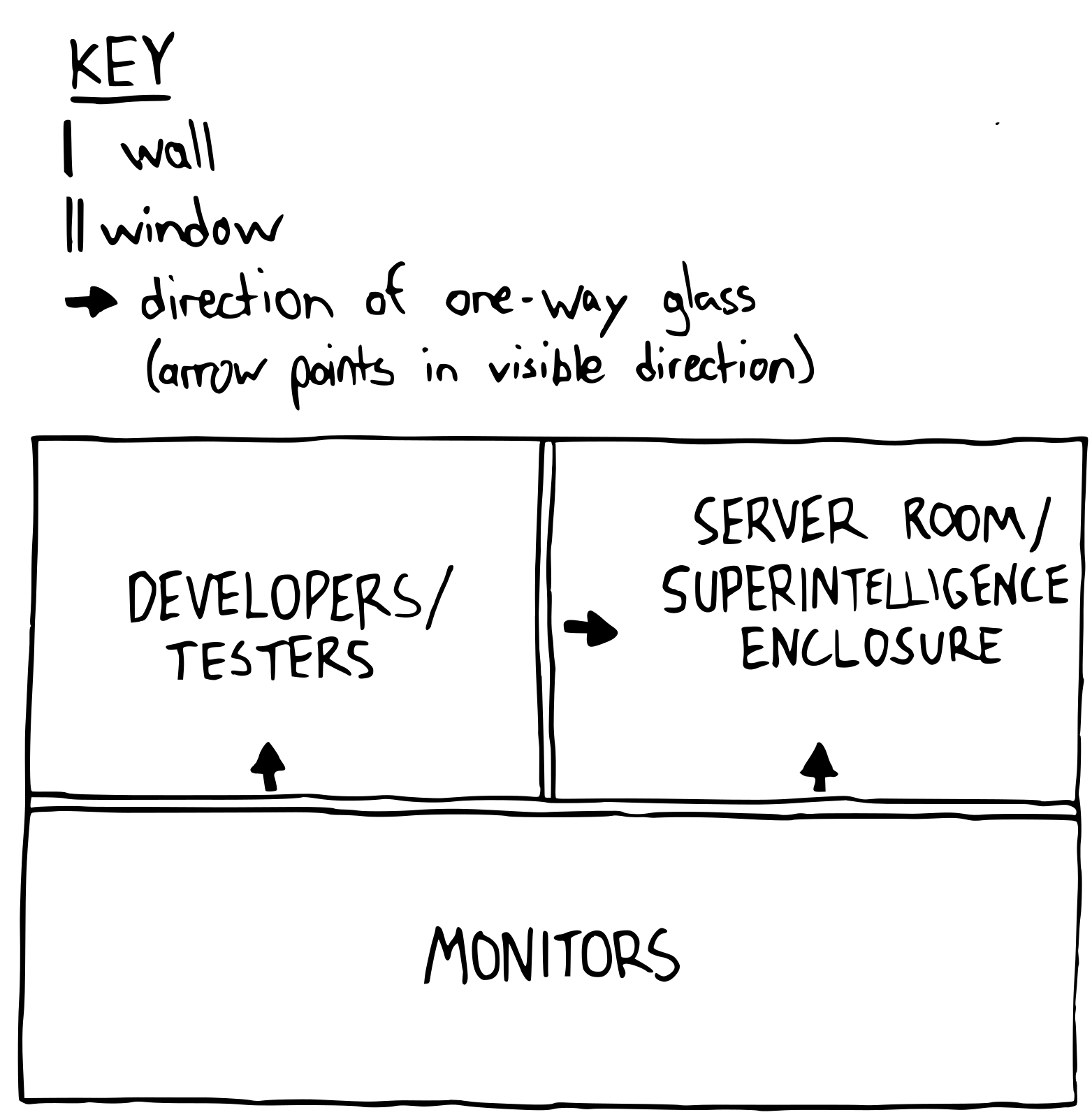
All systems part of the GPT model should be at the same physical location while testing and follow strict Role Based Access Control (RBAC) models, with access to the model only allowed in-person. There are three parties involved here: the tester or developer, the monitoring team, and the Superintelligence. The Superintelligence would not be able to connect outside of the floor or building in any way. The Superintelligence would be running on servers in their own room, with one-way glass walls on two sides. Next to this room, on one side, would be the developer area. Again, two sides being glass. The third room is for the monitors and spans between developers and the Superintelligence. Many might view this strategy as excessive, or too cautious - yet, the risk is far too high to be any sort of naive when it comes to Superintelligence.
It is probable that many of the existing players are following proper network segmentation practices as originally hoped. It is unlikely that they have the degree of physical security needed to safely develop AI models with capabilities exceeding humans. Their test environments are probably run on Azure (Microsoft) or AWS (Amazon) infrastructure. While this isn’t malice, the author of this post does believe that it is negligence.
Secretive Culty Superintelligence
We start this section by revisiting Sam Altman’s firing from OpenAI in November 2023. The details of these events were peculiar, with several prevalent theories:
- Hostile takeover
- Conflict of interest (Sam Altman runs many other AI-related startups)
- Negligence from Sam Altman (possibly failing to disclose details or a discovery to the board)
- Q* (AI model highly capable at math, unlike ChatGPT or GPT-4) (AI Explained YouTube)
- Early versions of Sora
- An undisclosed AGI or Superintelligence breakthrough
There was never a concrete conclusion to these events, aside from the fact that the employees of OpenAI ultimately petitioned to bring him back - just over 87% of them, foregoing work and tasks at hand until Sam came back to the company. At one point, Microsoft was going to spin up an entirely new department with Sam Altman and any employees that wanted to follow him to the tech behemoth. These efforts were promptly cancelled and operations resumed when Sam Altman returned to OpenAI just a few days after being forced out (2023, Time).
In the 2024 edition of these dramatic events, two of their top AI safety engineers quit, with one of them posting on X ‘safety culture and processes have taken a backseat to shiny products’ (2024, @janleike X / Twitter). With OpenAI recently releasing the best performing multimodal (text, voice, image) GPT model, GPT-4o, these staff changes are somewhat concerning.
The other high-profile employee that recently resigned, Ilya Sutskever, used to reportedly chant ‘FEEL THE AGI!’ with employees to spur a sense of community and purpose at OpenAI. But, was it more than just that? (2023, Futurism). Could Sam Altman have been removed from OpenAI because of Sora? Or the recently released GPT-4o? Or a more advanced AI model or product? Possibly, but let’s look at the facts.
- Sam Altman was temporarily ousted from his own company
- The largest tech giant (Microsoft) backed him up with capital and resources promised, for all existing employees and Sam
- They release demos for Sora
- They release GPT-4o and are once again are the most performant GPT model creator (Until Anthropic’s Claude Sonnet 3.5)
- Moments later, at least two engineers focused on Superintelligence alignment leave the company
The next section is sure to calm your nerves…
Regardless of the next section, it seems unlikely that secrecy of big advancements would be localized to OpenAI. Google, Amazon, and Meta could logically be doing the same. This then spurs the question, why wouldn’t these companies keep a Superintelligence private until they encounter worthy competition? After all, it would best be used internally to increase shareholder value, at least at first. OpenAI will have more dirty laundry in the news, alongside other companies when discoveries are made. This is when we enter the idea of a secretive Superintelligence, where company culture and subsequent drama surround opaque technological advancements.
Here’s the bottom line: an ultra-secretive arms race is in the bottom of the fifth inning. If these tech powerhouses are competing to reach AGI and Superintelligence, they will get there one way or another for better or worse. It comes down to who releases first, and more importantly - if they did it right.
OpenAI’s Recent Policy Change on Military Involvement
Continuing on with the thought of an AGI or Superintelligence breakthrough at OpenAI, these next developments are particularly interesting. For several years, OpenAI has had a known stance against involvement with the military or U.S. Government, outside of regulation discussions. This recently changed. OpenAI quietly removed their own guideline surrounding military involvement and announced a collaboration with DARPA on ‘cybersecurity tools’ (2024, TechCrunch). While this vague project is very intriguing, we’ll lean to speculation until there are more details or a product release of some sort.
OpenAI is now meeting with the government. In the author’s opinion, this is a significant red flag. It’s one thing to work with the military, but it is another thing to pull a total u-turn in moral compass. Could it be that OpenAI was forced to do so after disclosing Q* or another technological advancement to the government during Sam Altman’s ousting in November 2023? Their policy change occurred after Sam Altman’s ousting was attempted, after all. It’s possible that this is the first indication of government capture, forcing OpenAI to disclose technologies and open their doors to the U.S. government. Further backing up this argument is the recent news that OpenAI appointed a former ‘commander of U.S. Cyber Command and the director of the National Security Agency’ to their board of directors (2024, AP News). Admittedly, this appears to be a strategic move from OpenAI to address the ever-present risk of cyber attacks from nation states, insider threats, supply chain attacks, and more.
The military has historically been a hub for technological exploration and innovation - you wouldn’t be able to read this blog post without the foundational work they did on ARPANET (Wikipedia). Wouldn’t DARPA and the Department of Defense be interested in utilizing OpenAI’s next-generation model rather than what is publicly accessible to the world with GPT-3.5, GPT-4, and GPT-4o? They already do this for startups under OpenAI’s venture capital wing after all (This Week In Startups YouTube). Why wouldn’t OpenAI do the same for use cases that the government is interested in? Going further, the guardrails could still be under development or even intentionally removed for their extra special government client. How would the U.S. government realistically utilize this? To propagate democracy (read: domestic and international assertion of power) through media (read: propaganda created with assistance from OpenAI’s GPT models) and strategic interventionism (read: advancement of the Military AI Industrial Complex).
Mitigations (In Order of Importance)
Appreciation of Existence
Generally speaking, being present in the moment is worthwhile advice. As we grow older, the passage of time and scale shifts significantly. Unfortunately, it is easy to take things for granted over time. In both the current world, and a potential future world with Superintelligence, being present in the moment is crucial to being human and living a rewarding life. Being human and knowing how to acknowledge that is one of the best parts about living in the moment. Whether through spontaneous disaster, hidden motives, gradual erosion, or technical advancement - our own definition of what it means to be human will become extremely subjective. Make the most of it while you can.
With the release of Sora, there are more questions than answers for most people. More fear than optimism. More concern than intrigue. While this isn’t a bad thing and everyone should have their own opinions about it, this juxtaposition underscores why it is important to live in the moment. Do me a favor - take at least 60 seconds to look away from this blog post - look around, stand up, interact with your environment - but try not to think too hard.
…
What did you notice? Was it the crack in window moulding that you hadn’t seen before? Was it the way that the clouds moved across the sky, or trees flowing in the wind? Was it the the drip of a faucet? A fast car driving by? Regardless of your answer, living in the moment means taking the world in, right now, with admiration. Living in the moment means finding beauty in minute things or occurrences, even if you are waiting in line at the DMV.
There is nuance to everything. The world that we live in is bizarre, yet calculated. Unpredictable, yet largely immutable. Tangible, yet abstract.
We can quibble all we want about whether or not Sora is beneficial to society and what implications there are in the long term. Fact of the matter is - we exist in a time where we know what it means to be human, for this specific instant. That could change very quickly as we march into the future.
Security Words in IRL Relationships
Security Words are commonly used in secure, high-clearance environments as a way to confirm that there was a prior discussion surrounding access and responsibility. The words themselves, agreed upon between two people or entities (no more and no less), can be viewed as a sort of contract. This contract answers one question very easily: Are you who you say you are?
This question will be asked more often over time, regardless of any security clearance or specific setting. If you don’t have a tangible way to answer the question of whether or not someone is who they say they are, then the question is impossible to answer. This is a question you will need to be able to answer. Establishing security words for life, rather than work or governmental access, is crucial to survival in the 21st century. Starting this process with individuals important to you - a parent, partner, friend, or even frequent acquaintances - are all perfect examples of who to establish security words with.
These security words should be agreed upon in-person, face-to-face with the other individual. It is reasonable, albeit less secure in the long term, to establish these words over the phone and confirm in-person at a later date. In addition to in-person relationships, security words should be embraced by teams that work closely together, especially those more in the public eye for extortion or fraud - like a celebrity and their publicity team, members of a C-Suite, or politicians and existing members of government for example. Malicious actors are already leveraging voice models to impersonate CEOs (2024, Futurism). Ideally, these security words should be memorized. If there are too many words for you to keep track of, write them down on paper or stamp them in titanium (StampSeed) and store in a secure location.
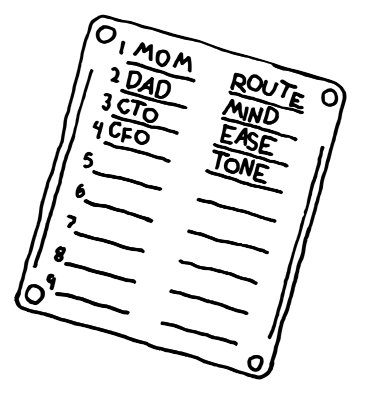
Why paper or titanium? An extra measure of security, essentially. In the event that a Superintelligence were to gain access to a computer or network of computers without prior notice or approval, nothing is safe. It is the same concept as a Bitcoin wallet - the 12 or 24 words used to represent your private key are at risk of being stolen with a software ‘hot’ wallet if compromised by malware or cryptojacking software. For this reason, having no record of your security words in the digital realm is encouraged.
General-Purpose Preparations
The preparations in this section are not directly related to AI, but moreso the ideology of ‘prepping’. This is effectively the idea that doom could present itself at any time, unexpectedly and instantaneously. At the most basic level, that includes necessities like bottled water, canned food, and first aid supplies. The fun thing about prepping is that you can take it as far as you want to. Passionate preppers likely have a stock of tactical gear like gas masks, hazmat suits, and ruggedized vehicles.
Any amount of the above is generally good to have, regardless of an AI-induced doomsday scenario. We encourage you to do your own research and prepare as needed, considering your w/acc preferences and personal risk / reward ratio.
Why mention this section though? Read Superintelligence by Nick Bostrom. Or, more broadly, seriously consider the arguments of those that want to stop the development of AI like Elizer Yudkowski or Connor Leahy. Fundamentally, the main idea is this: We don’t completely know how or why AI does certain things, and not knowing that means we don’t have a full picture of all motives or other, potentially malicious, emergent capabilities of a powerful enough model. A future Superintelligence, if it decides that there is no further use of humans, or even that we are getting in its way, could swiftly act on eradicating us. This isn’t a particularly endearing end to civilization (if that is possible to have). The author of this post will make it as difficult as possible for a Superintelligence to kill them.
Inclusion of Scarce Assets in a Portfolio
For this section, we break down the economic impacts of a societal shift to Artificial General Intelligence (AGI) and Superintelligence in three phases:
- Widespread job loss and panic
- Governmental band-aids and stopgap measures
- Post-labor economics
Scarce assets likely won’t fare well during phase 1 (job loss and panic). 2024 may mark the early beginnings of phase 1 with the release of Devin (Wikipedia) or other AI models like Sora and GPT-4o. Any scarce assets that people own at this time will likely be sold to cover expenses as the government puts together a plan. Phase 1 is characterized by a significant increase of the unemployment rate, especially when humanoid robots become more capable and prevalent. This increase in the unemployment rate would climb to over 35% and stay there for far longer than usual. Most people will likely be unhappy with this, sparking protests and civil unrest (like the self-driving car that was set on fire in San Francisco; 2024, Washington Post). Governments could say that this mass unemployment is temporary and that market forces will correct themselves following mass layoffs. Since this has been true for all other technological revolutions, that will likely remain true - but, it might be more difficult to navigate than before.
Phase 2 (governmental band-aids and stopgap measures) is where fixed supply assets could theoretically shine. A recent example of significant measures taken by governments was the COVID-19 pandemic. Many U.S. citizens received checks from the government for monetary assistance. Unfortunately, this also meant that inflation increased significantly over the following years. At the same time, most fixed-supply assets like Real Estate and Bitcoin reached new all-time highs. It is possible that amidst large-scale job loss, the government opts to take similar actions - offering one-off or recurring checks to individuals. So, the monetary appreciation and monetary success of fixed supply assets may become a self-fulfilling prophecy and / or market force [yet again]. Most people leaving the workforce in the future will likely remember the COVID-19 pandemic. It’s entirely possible that this solution will not be met with praise this time, but rather concern about inflation and an increased lack of confidence that the U.S. government can properly manage the situation. Enter, the trifecta of fixed supply assets: Real Estate, Gold, and Bitcoin.
The fixed supply trifecta will likely thrive in phase 3 (post-labor economics) as well. There are some ideas surrounding what an economy would look like in a post-labor society, ranging from Universal Basic Income (UBI) to utilizing humanoid robots to complete contracted jobs (David Shapiro YouTube). While dystopian and borderline depressing, content creation will likely be the most popular form of employment in post-labor economics. If AI-powered technologies reach the prevalence that we assume in this blog post, there will only remain a few select employment opportunities for humans. For a long time, people have used Real Estate as a savings technology, passing it down from generation to generation and leveraging it as a source of income when needed - especially in the United States and China. This should only accelerate. Humble homesteads today will, for better or worse, be simply unattainable to future generations. Gold is another savings technology that many people use, but far less often than Real Estate. Bitcoin is becoming increasingly popular as a savings technology, especially for those starting their career with already dwindling prospects of owning a home.
Fundamentally speaking, the author of this blog post is long-term bullish on Bitcoin and other fixed supply assets, but mostly Bitcoin. In the post-labor economic future (Phase 3), the cost of items should decrease significantly alongside the reduction of labor costs (Corporate Finance Institute). Even though the linked article primarily discusses decreased costs when manufacturing in higher volume, technological deflation would come from cheaper cost of working hours for humanoid robots compared to humans. One might assume that this would negatively impact assets like Bitcoin and Gold, but it could actually be the opposite.
Those that have a long-term view of fixed supply assets, even in post-labor economics, could be rewarded by choosing them as savings technologies instead of government-issued FIAT currencies. With FIAT currencies around the world failing, a return to fixed supply monetary standards of the past will look increasingly attractive to governments as they inflate away their own ability to collect taxes and pay debt. Volatility (read: rate of price fluctuations) will only continue to increase over time as human-contracted and independent AI agents navigate the economy as well.
Digital Footprint Minimization
The more data an AI model has, the better it is at generalizing and extrapolating on the base data - remember, it is their basis for pattern generation. Therefore, the less data that the AI has to know what you look like, how you write, how you behave, what your preferences are - the better. These data, especially when present on the internet, can be used against you in the future. Your image, with sufficient online gunpowder, could easily be leveraged for scamming relatives and people you know. Given enough details, alongside data theft and credential compromise, large-scale identity theft becomes trivial.
If you live a very online and public life, this needs to be part of your risk vs reward considerations (read: w/acc; risk vs. productivity). We write this blog post with full understanding of the impacts, avoiding posting images of the author’s physical likeness. Content creators of the future may take extreme measures to anonymize themselves and protect against digital likeness theft.
It’s also worth noting that we already live in the age of surveillance capitalism. The harvesting, packaging, and reselling of your online data and browsing habits is largely unavoidable. The NSA (National Security Agency) even admitted they buy it under the radar without warrants - how bizarre is it that your own tax dollars are used to surveil yourself? (2024, Ars Technica) There are a few options to chip away at this, starting with convenient browser plugins (uBlock Origin, Privacy Badger), self-hosted alternatives to online storage (Nextcloud), media consumption (Jellyfin, Emby, Others), bank accounts (Hardware wallets for Bitcoin like the Blockstream Jade and / or Stablecoins with Trezor) or other offerings, instant messaging (Matrix), social media (Mastodon, Nostr), network security (PiHole, PfSense), password management (BitWarden, Others), and more straightforward all in one sovereign server solutions (Umbrel, Start9).
It’s worth noting here that perfection, zero digital footprint, is largely unattainable. We can strive to minimize our online footprint, but this is only 100% possible if you decide to not use a networked computer or phone at all in the modern era. Those who minimize their use of technology significantly due to risk / reward evaluations will likely consider themselves AI-age luddites; no leveraging of platforms that use AI, minimal web browsing, local networking or VPN-isolated networks, person-to-person transmission of large data files, and more undergroud strategies. People will likely group geographically or virtually depending on how they view what it means to be human in the modern era.
Skepticism and Research Skills
AI has already proven itself as a useful tool - assisted brainstorming, distillation of complex topics, starting a new project - the possibilities are already impressive and growing every day. We must discuss the idea of ‘blind trust’, where some people in the future will view the output of an AI as ground truth, utilizing it as a jumping off point without asking the question: How accurate is this information?
It’s counter-intuitive to double check all information that generative models output, and that isn’t the requirement. Careful consideration of individual root details presented, especially if these details are provided publicly or impact other human lives, is important to complete further research. Consider interpreting the output of a GPT model like a tree, with branches and a root or trunk. This root could encompass the main concept or important figure that you are relying on for further research. You must do your own due diligence when interpreting output from GPT models. In legal practice for example, this would begin by verifying that specific case law referenced by an AI model actually exists (2023, Reuters). Be reasonable. Be skeptical. If the output of a generative AI model sounds too good to be true or is too close to what you were looking for, it probably is. Maintaining research skills should feel easy if you follow these directions.
Cautious, Yet Curious Exploration
Innovation is happening at breakneck speeds. We hope that the introduction made this clear. It is already difficult to keep up with new innovations and releases, but it is also exciting to be alive and keep tabs on the commercial and open-source AI space. The w/acc methodology mentioned earlier embraces experimentation and exploration. Spend time generating images, just to see what the technology can create. Spend time just talking with ChatGPT to inquire about reasoning and curiousity. Run open-source models just to see how capable they are (spoiler alert, surprisingly versatile). It’s important to not only keep up to date on AI news, but also experiment responsibly with the new technologies. Individuals have a difficult time fully grasping pitfalls and successes of a technology without applying it to their own day-to-day life. This doesn’t mean you need to be an AI power user, far from it, but it does mean that it’s crucial to increase awareness of what certain advancements are and how they may impact both societies and individuals.
Remember, there’s a storm on the horizon. Don’t forget your umbrella.
Appendix
Not By AI
The author of this post is proud to follow the ‘Not By AI’ methodology (not by AI). No more than 10% of these blog posts are created or assisted by Artificial Intelligence. All illustrations are done by hand on pen and paper. They are scanned digitally, turned into bitmaps, colored by line and background (using Inkscape), then scaled and cropped (using GIMP, GNU Image Manipulation Program).
Posts are both written and reviewed by one or multiple humans. Some, or all, of the content may be input into a large language model, but it is not used for editing guidance or verbiage - merely content discussion and high level concept contemplation.
Resources
References and Media Bias
- Crunchbase News (AllSides; center)
- TechCrunch (AllSides; center)
- Reuters (AllSides; center)
- Ars Technica (AllSides; center)
- Time (AllSides; leans left)
- Wired (AllSides; center)
- Associated Press News (AllSides; leans left)
AI YouTube Channels
- YouTube David Shapiro (Apparent futurist; generally covers Moonshots)
- YouTube Wes Roth (Sensationalist; covers Moonshots and Malice)
- YouTube AI Explained (Level-headed analyst; covers Moonshots and Malice)
- YouTube Lex Fridman (Skilled podcaster; doesn’t always cover AI, worth watching discussions with Sam Altman, Eliezer Yudkowsky, Yann LeCun, and more)
- YouTube Impact Theory with Tom Bilyeu (Borderline sensationalist; some very insightful guests that have wide ranges of opinions)
- YouTube Peter H. Diamandis (Futurist; mostly covers AI, some business / entrepreneurship topics as well)
Bitcoin Resources
- YouTube What Bitcoin Did (Bitcoin-specific channel, frequent interviews with wide range of guests)
- YouTube Preston Pysh (Bitcoin podcaster, focuses mostly on cool new Bitcoin technologies and economics)
- YouTube Benjamin Cowen (Bitcoin / Macroeconomics, nuanced content channel)
- Bitcoin Treasuries bitcontreasuries.net (Index of public companies and ETFs that hold Bitcoin)
News
- Artificial Intelligence Incident Database AIID
- Singularity subreddit (Large Advancements in AI, big questions and discussions)
- Hacker News (Latest technology news, generally lots of startup and AI related content)
- The Hacker News (Cybersecurity focused news publication)
- Bleeping Computer (Cybersecurity focused news publication)
Self-Sovereignty
- Easy to install self-sovereign operating systems: Start9, Umbrel
- Reddit community focused on running software at home: /r/homelab
- Repository of locally-run AI Models: HuggingFace
- Software needed for local LLMs: GitHub ggerganov/llama-cpp
- Other self-hosted software mentioned in this post
Previous Iterations of This Blog Post
Originally, the author intended to post monthly to this blog. Over time, we hope is that this goal is achieved. The first draft of this blog post was written on March 1st, 2023. Below, a historical record of drafts created and discarded are provided:
| Title | Date |
|---|---|
| AI As a Lens | March 1st, 2023 |
| Some Innovations in Using ChatGPT | March 7th, 2023 |
| Blah Blah ChatGPT | March 26th, 2023 |
| Living With Generative and Imitative AI | June 18th, 2023 |
| GPT Part I: Living With Generative and Imitative AI | July 2nd, 2023 |
| GPT Part I: 4 i’s and 4 d’s on Generative AI | July 4th, 2023 |
| Superintelligence: A Present-Day Book Review | December 8th, 2023 |
| Superintelligence: Precedents, Problems, and Practices for the Revolution | December 16th, 2023 |
| We Aren’t Ready | February 19th, 2024 |
| Moonshots, Malice, and Mitigations | March 24th, 2024 |
Acknowledgements
- SethRogensLeftNut (Editor)
- Peers (Draft review, discussion)
- GPT-4 (Supplemental assistance with Transformer concepts and some minor vocabulary choices)
- Claude 3.5 Sonnet (Additional review and discussion)